1. 스타벅스 옆엔 이디야와 올리브영이 있다?
https://kid.chosun.com/site/data/html_dir/2022/06/02/2022060202963.html
프랜차이즈 브랜드 立地<입지> 선택의 법칙… 스타벅스 옆엔 이디야가 있다?
kid.chosun.com
2. 스타벅스 정보 크롤링

import time
# re : 정규표현식 모듈
import re
import pandas as pd
from selenium import webdriver
# ActionChains: 마우스나 키보드와 같은 복잡한 사용자 상호작용을 시뮬레이션하는 데 사용
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
# WebDriverWait: 특정 요소가 나타날 때까지 대기하는 데 사용
from selenium.webdriver.support.ui import WebDriverWait
# expected_conditions: 특정 조건이 충족될 때까지 대기하는 데 사용
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup
def fetch_starbucks():
starbucks_url = 'https://www.starbucks.co.kr/index.do'
driver = webdriver.Chrome()
driver.maximize_window() # 브라우저 창 최대화
driver.get(starbucks_url)
time.sleep(1)
# '매장 찾기' 버튼 클릭
action = ActionChains(driver)
# 첫 번째 메뉴인 'STORE'에 마우스 오버
first_tag = driver.find_element(By.CSS_SELECTOR,'#gnb > div > nav > div > ul > li.gnb_nav03')
# '매장 찾기' 버튼을 검사 후 a태그로 copy -> selcetor로 변경
second_tag = driver.find_element(By.CSS_SELECTOR,'#gnb > div > nav > div > ul > li.gnb_nav03 > div > div > div > ul:nth-child(1) > li:nth-child(3) > a')
# STORE 메뉴에 마우스 오버 후 '매장 찾기' 클릭
action.move_to_element(first_tag).move_to_element(second_tag).click().perform()
# 최대 10초까지 기다리기 -> 서울 클릭할 수 있는지 체크만 해준다.
seoul_tag = WebDriverWait(driver,10).until(
# 클릭할 수 있는지 테스트
EC.element_to_be_clickable(
(By.CSS_SELECTOR,'#container > div > form > fieldset > div > section > article.find_store_cont > article > article:nth-child(4) > div.loca_step1 > div.loca_step1_cont > ul > li:nth-child(1) > a')
)
)
seoul_tag.click()
# 데이터 저장할 리스트 준비
store_list = []
addr_list = []
lat_list = []
lng_list = []
WebDriverWait(driver, 5).until(
# 이 안에 돔 요소가 있는지 확인
EC.presence_of_all_elements_located((
By.CLASS_NAME,'set_gugun_cd_btn'
))
)
gu_elements = driver.find_elements(By.CLASS_NAME,'set_gugun_cd_btn')
WebDriverWait(driver, 5).until(
# 클릭할 수 있는지 확인
EC.element_to_be_clickable(
(By.CSS_SELECTOR,'#mCSB_2_container > ul > li:nth-child(1) > a')
)
)
gu_elements[0].click()
WebDriverWait(driver, 5).until(
EC.presence_of_all_elements_located(
(By.CLASS_NAME,'quickResultLstCon')
)
)
req = driver.page_source
soup = BeautifulSoup(req, 'html.parser')
stores = soup.find('ul', class_='quickSearchResultBoxSidoGugun').find_all('li')
for store in stores:
store_name = store.find('strong').text
store_addr = store.find('p').text
store_addr = re.sub(r'\d{4}-\d{4}$', '', store_addr).strip()
store_lat = store['data-lat']
store_lng = store['data-lng']
# 데이터 리스트에 추가
store_list.append(store_name)
addr_list.append(store_addr)
lat_list.append(store_lat)
lng_list.append(store_lng)
df = pd.DataFrame({
'store': store_list,
'addr': addr_list,
'lat': lat_list,
'lng': lng_list
})
driver.quit() # 브라우저 종료
return df
starbucks_df = fetch_starbucks()
# sig 붙이면 엑셀에서 한글 깨짐 방지
starbucks_df.to_csv('starbucks_seoul.csv', index=False, encoding='utf-8-sig')
print('스타벅스 매장 정보가 starbucks_seoul.csv에 저장되었습니다.')
3. 데이터 전처리
import pandas as pd
df_starbucks = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/Python_colab/Web Service/11. 데이터 분석/data/starbucks_seoul.csv')
df_starbucksdf_starbucks = df_starbucks.set_axis(['지점명','지점주소','지점위도','지점경도'],axis=1).reset_index(drop=True)
df_starbucksdf =pd.read_csv('/content/drive/MyDrive/Colab Notebooks/Python_colab/Web Service/11. 데이터 분석/data/소상공인시장진흥공단_상가(상권)정보_20250331/소상공인시장진흥공단_상가(상권)정보_서울_202503.csv',low_memory=False)
df.head()df.info()shop = ['이디야', '이디아커피', '올리브영', '컴포즈커피', '빽다방', '백다방', '메가커피', '메가엠지씨', '메가MGC']# 메가커피(메가엠지씨) 데이터 필터링
# contains(): 특정 문자열 포함 여부에 따라 True, False를 반환
# case=False: 대소문자를 구분하지 않겠다는 설정
# na=False: 결측치(NaN) 처리. 결측치가 있는 경우 False로 간주하여 결과에 포함되지 않음
df[df["상호명"].str.contains("메가엠지씨", case=False, na=False)]df[df["상호명"].str.contains("메가커피", case=False, na=False)]df[df["상호명"].str.contains("메가MGC", case=False, na=False)]# 한번에 다 찾기
df[df["상호명"].str.contains('메가커피|메가엠지씨|메가MGC', case=False, na=False)]df_shop = df.copy()
# extract(): 특정 문자열을 포함하고 있으면 그 문자열을 반환, 포함하고 있지 않으면 NaN을 반환
df_shop['상호명'] = df_shop['상호명'].str.extract('({})'.format('|'.join(shop)))
# shop = ['이디야', '이디아커피', '올리브영', '컴포즈커피', '빽다방', '백다방', '메가커피', '메가엠지씨', '메가MGC']
# 이디야|이디아커피|올리브영|컴포즈커피|빽다방|백다방|메가커피|메가엠지씨|메가MGC
# 위에 해당되는 상호명 제외하고 다른 상호명은 다 NaN으로 날리기
df_shop['상호명']
# subset : 특정 컬럼이 아니면 다 지움
df_shop = df_shop.dropna(subset=['상호명']).iloc[:, [0, 1, 14, 37, 38]].reset_index(drop=True)
df_shop
# 상호명 통일시키기
df_shop['상호명'] = df_shop['상호명'].str.replace('메가엠지씨', '메가커피', regex=False)
df_shop['상호명'] = df_shop['상호명'].str.replace('메가MGC', '메가커피', regex=False)
df_shop['상호명'] = df_shop['상호명'].str.replace('이디아커피', '이디야', regex=False)
df_shop['상호명'] = df_shop['상호명'].str.replace('백다방', '빽다방', regex=False)
df_shop
# 상호명 통합됐는지 확인하기
df_shop[df_shop['상호명'].str.contains('메가엠지씨', na=False)]print(df_shop.shape)
print(df_starbucks.shape)
# (2310, 5)
# (644, 4)# cross-join으로 서울 전역을 다 연결시킨다.
# 그 중에서 가장 최단거리를 가져오면 된다.
# cross : 하나당 모두 다
df_cross = df_shop.merge(df_starbucks, how='cross')
df_cross
# 1487640 rows × 9 columns
4. Haversine eqn
Haversine 공식은 구체(구면) 위의 두 점(위도와 경도로 표시됨) 사이의 최단 거리(대원 거리, great-circle distance)를 계산하는 방법입니다. 이 공식은 GPS 좌표(위도와 경도)를 활용하여 지구 표면 위의 거리 계산에 널리 사용됩니다.
** 유클리드 거리 & 맨하탄 거

from haversine import haversine# 모든 행에 lambda식으로 정리
# 위도, 경도 : 서울 상업지
# 지점위도, 지점경도 : 스타벅스
df_cross['거리'] = df_cross.apply(lambda x: haversine([x['위도'], x['경도']], [x['지점위도'], x['지점경도']], unit='m'), axis=1)
df_cross# 상가업소번호로 그룹을 맺고 거리가 짧은거 추출
# 개별 매장들과 스타벅스와의 최소 거리
df_dis = df_cross.groupby(['상가업소번호','상호명'])['거리'].min().reset_index()
df_dis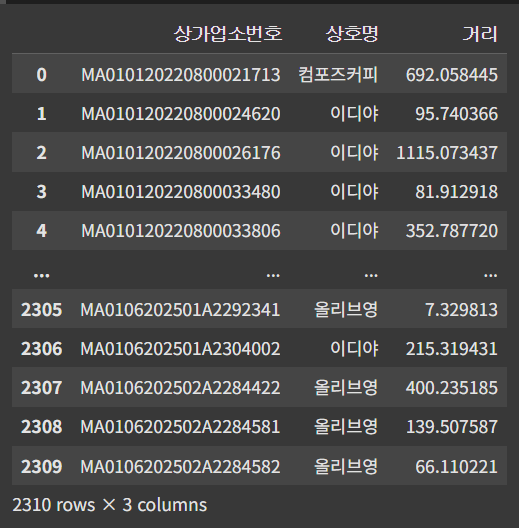
# 각 프렌차이즈 별 스타벅스와의 평균 거리
df_dis.groupby('상호명')['거리'].mean()
# agg(): 다중 집계작업을 간단하게 해주는 함수
df_dis.groupby(['상호명'])['거리'].agg(['mean','count'])
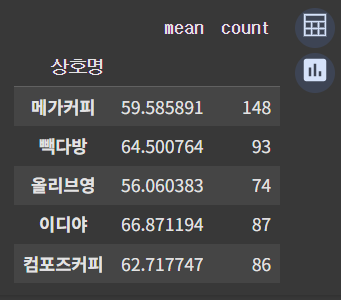
# 거리를 입력하면 프렌차이즈 별 스타벅스와의 평균거리와 매장개수를 출력하는 함수
def distance(x):
dis = df_dis['거리'] <= x
return df_dis[dis].groupby('상호명')['거리'].agg(['mean', 'count'])
# 100m 이내
distance(100)
5. 차트 시각화
!pip install pandasechartsdf_100 = distance(100).reset_index()
df_100import IPython
from pandasecharts import echart
df_100.echart.pie(x='상호명', y='count', figsize=(600, 400),
radius=['20%', '60%'], label_opts={'position':'outer'},
title='커피 프렌차이즈의 입점전략은 과연 스타벅스 옆인가?',
legend_opts={'pos_right':'0%', 'orient':'vertical'},
subtitle='100m 이내 매장수', init_opts={'bg_color': 'white'}).render()
IPython.display.HTML(filename='render.html')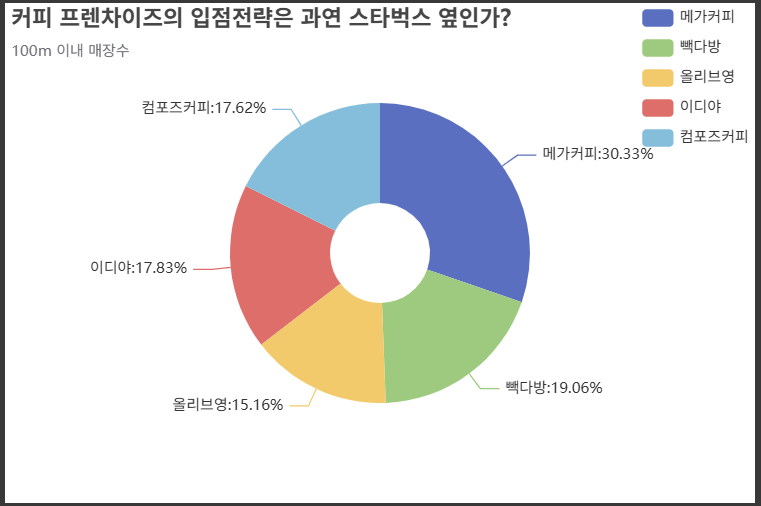
from pyecharts.charts import Timeline, Grid
tl = Timeline({'width':'600px', 'height':'400px'})
for i in [1000, 100, 50, 30]:
df_d = distance(i).reset_index()
pie1 = df_d.echart.pie(x='상호명', y='count', figsize=(600, 400),
radius=['20%', '60%'], label_opts={'position':'outer'},
title='커피 프렌차이즈의 입점전략은 과연 스타벅스 옆인가?',
legend_opts={'pos_right':'0%', 'orient':'vertical'},
subtitle='{}m 이내 매장수'.format(i), init_opts={'bg_color': 'white'})
tl.add(pie1, '{}m'.format(i)).render()
IPython.display.HTML(filename='render.html')
'Python' 카테고리의 다른 글
| 서울시 공공자전거 실시간 대여정보 (2) | 2025.07.22 |
|---|---|
| 소상공인시장진흥공단_상가정보 데이터셋 (3) | 2025.07.21 |
| Online Retail (0) | 2025.07.21 |
| Matplotlib (0) | 2025.07.21 |
| Pandas (0) | 2025.07.17 |